system-design-bangla
সিস্টেম ডিজাইন বাংলা
এটি একটি রিপোজিটরি যেখানে সিস্টেম ডিজাইন এর মৌলিক জিনিসগুলো নিয়ে আলোচনা করা হয়েছে।
এই টিউটোরিয়াল এর উদ্দেশ্য আপনাকে মৌলিক জিনিসগুলোর ধারণা দেয়া। ভালো লাগলে star, watch কিংবা fork ক্লিক করে রাখতে পারেন।
সূচিপত্র
- Section 1: System Design
- Section 2: Database Engineering
- Section 3: B+ Tree and Database Indexing
- Section 4: Database Transaction
- Section 5: Client Server Architecture
- Section 6: Reliability
- Section 7: Performance Metrics
- Section 8: Distributed System
- Section 9: Domain Name System
- Section 10: Transmission Control Protocol
- Section 11: User Datagram Protocol
- Section 12: HTTP, TLS and HTTPS
- Section 13: What happens when you type a URL in your browser
- Section 14: Concurrency and Parallelism
- Section 15: High Concurrency Control
- Section 16: Functional and Non Functional Requirements
- Section 17: Back Of the Envelope Estimation
- Section 18: Authentication and Authorization
- Section 19: Stateful and Stateless Architecture
- Section 20: Proxy
- Section 21: REST API
- Section 22: Scalability
- Section 23: Database Sharding
- Section 24: Database Replication
- Section 25: Caching
- Section 26: Content Delivery Network
- Section 27: Rate Limiter
- Section 28: CAP Theorem
- [Section 29: Consistent Hashing] (চলমান)
- Section 30: Polling, Web Socket, Server-Sent Events and Webhooks
- [Section 31: Stream and Batch Processing] (চলমান)
- Section 32: Message Queue
- [Section 33: rpc, gRpc] (চলমান)
- Section 34: Single Sign-On
- Section 35: Elasticsearch
- Section 36: Bloom Filter
- [Section 37: Load Balancing Algorithms] (চলমান)
- Section 38: How OAuth2 works
- [Section 40: Serverless Architecture] (চলমান)
- Section 41: How to choose the right database for your application
- Section 42: Designing reliable Batch Processing for large-scale data
- Section 43: High Availability best practices by Netflix
- Section 44: Production Outages
- Section 45: Real World Problems
- Section 46: Resources
🛣️ System Design Learning Path
এই Learning Path অনুসরণ করলে beginner থেকে advanced পর্যন্ত ধাপে ধাপে পড়া যাবে।
🟢 Basic Architecture
- Section 1: System Design
- Section 5: Client Server Architecture
- Section 19: Stateful and Stateless Architecture
- Section 22: Scalability
🌐 Networking Basics
- Section 9: Domain Name System
- Section 10: Transmission Control Protocol
- Section 11: User Datagram Protocol
- Section 12: HTTP, TLS and HTTPS
- Section 13: What happens when you type a URL in your browser
🧱 Backend Fundamentals
- Section 16: Functional and Non Functional Requirements
- Section 17: Back Of the Envelope Estimation
- Section 18: Authentication and Authorization
- Section 21: REST API
- Section 20: Proxy
🗄️ Database Basics
- Section 2: Database Engineering
- Section 3: B+ Tree and Database Indexing
- Section 4: Database Transaction
- Section 41: How to choose the right database for your application
🟡 Performance & Reliability
- Section 6: Reliability
- Section 7: Performance Metrics
- Section 14: Concurrency and Parallelism
- Section 15: High Concurrency Control
🧵 Distributed Systems Core
- Section 8: Distributed System
- Section 28: CAP Theorem
- Section 29: Consistent Hashing
- Section 27: Rate Limiter
📦 Data Scaling & Performance Optimization
- Section 23: Database Sharding
- Section 24: Database Replication
- Section 25: Caching
- Section 26: Content Delivery Network
🔁 Async & Communication Patterns
- Section 30: Polling, Web Socket, Server-Sent Events and Webhooks
- Section 31: Stream and Batch Processing
- Section 32: Message Queue
- Section 33: rpc, gRpc
🔐 Security & Identity
⚙️ Advanced Infrastructure Concepts
- Section 35: Elasticsearch
- Section 36: Bloom Filter
- Section 37: Load Balancing Algorithms
- Section 40: Serverless Architecture
🏗️ Production & Real-World Systems
- Section 43: High Availability best practices by Netflix
- Section 44: Production Outages
- Section 45: Real World Problems
📚 References
Section 1: System Design
যখন আমরা একটি অ্যাপ্লিকেশন ডেভেলপ করি, তখন একটি নির্দিষ্ট ডিজাইন অনুসরণ করা জরুরি। এর প্রধান কারণ হলো, অ্যাপ্লিকেশনটি যাতে বর্তমানে এবং ভবিষ্যতে কোনও সমস্যা ছাড়াই ভালভাবে কাজ করতে পারে। বিশেষ করে, যদি অ্যাপ্লিকেশনটি এক সময় প্রচুর ব্যবহারকারী পেয়ে থাকে, তখন এটি প্রচুর লোড সহ্য করতে সক্ষম হতে হবে এবং কোনো কানেকশন বিচ্ছিন্নতা বা পারফরম্যান্সের অবনতি ছাড়াই কাজ করতে হবে। এই ধরনের ডিজাইনকেই সিস্টেম ডিজাইন বলা হয়।
(এই স্পেসিফিক সিস্টেম ডিজাইন মূলত ব্যাকএন্ড ইঞ্জিনিয়ারিং এর সাথে সম্পৃক্ত।)
Section 2: Database Engineering
সিস্টেম ডিজাইন করার সময় ডেটাবেস খুবই গুরুত্বপূর্ণ বিষয়। কোন কোন রকমের এপ্লিকেশন এর জন্য কোন কোন রকমের ডেটাবেস ব্যবহার করবেন, ডেটাবেসের টেবিলের স্ট্রাকচার কেমন, টেবিল কলাম এর ডেটা টাইপ, টেবিল size ইত্যাদি জানা আমাদের দরকার।
এপ্লিকেশন ডেভেলপ করার সময় আমাদের কাজ অনুযায়ী ডেটাবেস নির্বাচন করতে হয়। সাধারণত, আমরা প্রধান দুই ধরনের ডেটাবেস ব্যাবহার করে থাকি - SQL(রিলেশনাল) ডেটাবেস এবং NoSQL(নন-রিলেশনাল) ডেটাবেস। আমরা কেমন বা কোন ধরণের ডাটা ষ্টোর করতে চাই, কিভাবে ষ্টোর করতে চাই, আমাদের কাজের পদ্ধতি ইত্যাদি প্রয়োজন অনুযায়ী ডেটাবেস বাছাই করতে হয়। ডাটার ধরন অনুযায়ী ডেটাবেসগুলো আমাদের ভিন্ন ভিন্ন সুবিধা দিয়ে থাকে।
| SQL | NoSQL |
|---|---|
| টেবিলের মধ্যে ডাটা স্টোর করা হয়, যেখানে প্রতিটি সারি একটি এন্টিটি এবং প্রতিটি কলাম একটি ডাটার বৈশিষ্ট্য নিদের্শন করে। টেবিলগুলোর মধ্যে relation থাকে। | কোন প্রকার relation ছাড়া ডাটা বিভিন্নভাবে ষ্টোর করে থাকে। যেমনঃ key-value, graph, document ইত্যাদি। |
| নির্দিষ্ট স্কিমা অনুযায়ী ডাটা স্টোর করা হয়। (ডাটাবেস পরিবর্তনের মাধ্যমে স্কিমা পরবর্তীতে পরিবর্তন করা যায়।) | NoSQL ডাটাবেসে ডাইনামিক স্কিমা থাকে, অর্থাৎ স্কিমা পরিবর্তনযোগ্য। |
Section 3: B+ Tree and Database Indexing
প্রথমে আমাদের বুঝতে হবে, B+ ট্রি কি এবং কেনো প্রয়োজন?
এটি একটি self-balancing Tree Data Structure। যা ডেটাবেসে ব্যবহার করা হয় Efficiently Data Retrieve করার জন্য। B+ ট্রি হলো Balanced Tree Index Structure যার প্রতিটি নোডে একাধিক key সংরক্ষণ করে, যা এটিকে ঐতিহ্যবাহী বাইনারি সার্চ ট্রির(Binary Search Tree) তুলনায় অনেক বেশি কার্যকর করে তুলে, বিশেষ করে বড় ডেটাসেটের জন্য।
Section 4: Database Transaction
ডাটাবেজ ট্রানজাকশন এই সমস্ত প্রশ্ন বা সমস্যার সমাধান করতে পারে:
-
ডাটাবেজ সফটওয়্যার বা হার্ডওয়্যার যে কোনো সময় fail হতে পারে। (write অপারেশনের মাঝখানেও)
-
নেটওয়ার্কে বাধা আসতে পারে, যা অ্যাপ্লিকেশনকে ডাটাবেজ থেকে অপ্রত্যাশিতভাবে বিচ্ছিন্ন করতে পারে।
-
একাধিক ক্লায়েন্ট একই এন্ট্রি আপডেট করার চেষ্টা করতে পারে, যার ফলে একে অপরের পরিবর্তনগুলি ওভাররাইট হতে পারে।
-
একটি ক্লায়েন্ট ডাটাবেজ থেকে এমন তথ্য পড়তে পারে যা সম্পূর্ণরূপে Commit করা হয়নি, ফলে তথ্যটি অপ্রাসঙ্গিক বা অসংগতিপূর্ণ হতে পারে।
-
ক্লায়েন্টদের মধ্যে concurrency বা race condition এর কারণে অপ্রত্যাশিত বাগ তৈরি হতে পারে।
উপরের পয়েন্টগুলোর উত্তর পেতে হলে নিচের টপিকগুলো বুঝতে হবে।
ডাটাবেসে Transaction বলতে বোঝায় একাধিক READ এবং WRITE অপারেশনকে একটি লজিক্যাল ইউনিট এর মধ্যে আবদ্ধ করা। এর ফলে, সমস্ত READ এবং WRITE অপারেশন একসাথে একটি একক অপারেশন হিসেবে বিবেচিত হয়। অর্থাৎ, যদি সব অপারেশন সফলভাবে সম্পন্ন হয়, তবে COMMIT করা হবে, আর যদি কোনো একটি অপারেশন ব্যর্থ হয়, তবে ROLLBACK এর মাধ্যমে পূর্বের অবস্থা ফিরিয়ে নেওয়া হবে।
সাধারণত Transaction এভাবে শুরু হয়,
BEGIN
SELECT * FROM users
UPDATE users SET username=“lahin” WHERE id=224
COMMIT
আপনি Prisma দিয়ে লিখতে গেলে,
await prisma.$transaction(async (prisma) => {
const users = await prisma.users.findMany();
await prisma.user.update({
where: { id: 224 },
data: { username: "lahin" },
});
});
🔗 আরও পড়ুন: ডাটাবেস ট্রানসাকশান
Section 5: Client Server Architecture
ক্লায়েন্ট রিকুয়েস্ট করবে সার্ভারকে কিছু স্পেসিকিফ রিসোর্স এর জন্য, সার্ভার সেই রিকুয়েস্ট পাওয়ার পর সে তার যাবতীয় প্রসেস শেষ করে ক্লায়েন্টকে রেসপন্স দিয়ে দিবে, এটি ক্লায়েন্ট সার্ভার আর্কিটেকচার।
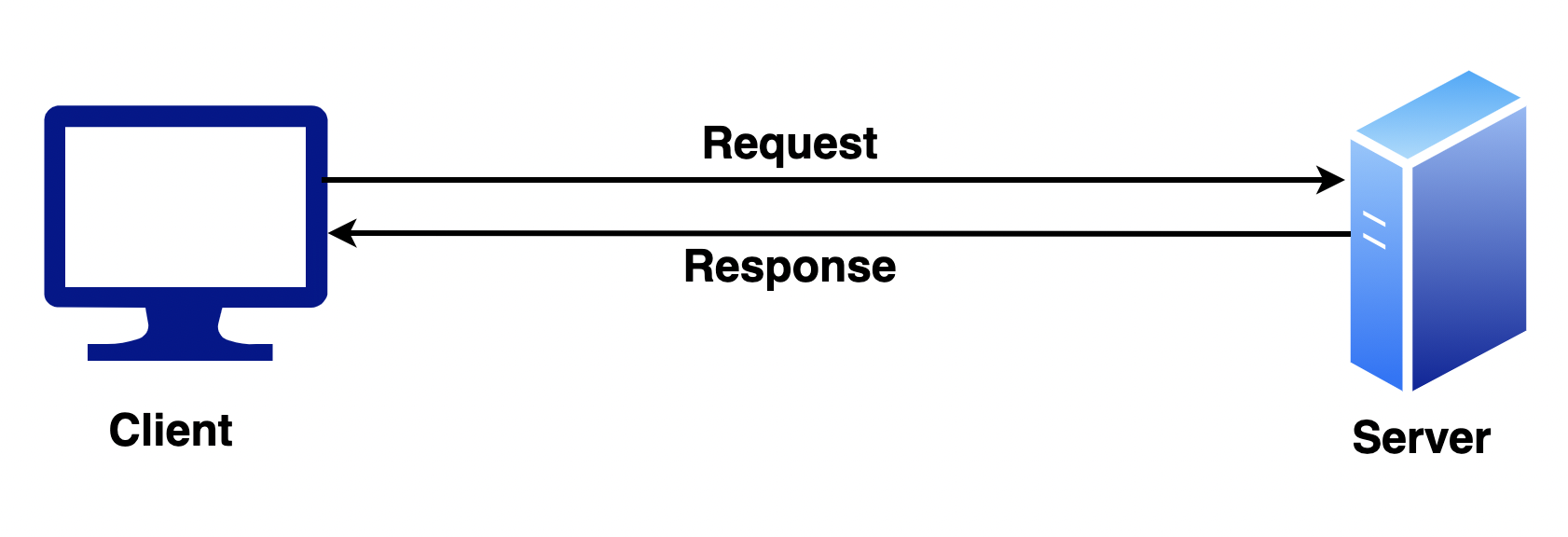
আমাদের সব উদাহরণ থাকবে ক্লায়েন্ট সার্ভার আর্কিটেকচারের উপর ভিত্তি করে।
Section 6: Reliability
সিস্টেম যদি কোনো প্রকারের Fault/Error থাকার পরও ভালোভাবে কাজ করতে পারে কিংবা সিস্টেমটি যদি বন্ধ না হয়, তবে সেই সিস্টেমটি Reliable। আমাদের মনে রাখতে হবে এক বা একাধিক Fault এর কারণে সিস্টেম Failure হতে পারে।
Fault এরকম হতে পারে কোনো user সিস্টেমটি কে এমনভাবে ব্যবহার করেছে যাতে কোনো Failure হয়ে গেল, সেটা ইচ্ছাকৃত বা অনিচ্ছাকৃতভাবেও হতে পারে, তখন যদি সিস্টেমটি বন্ধ না হয়ে কোনো প্রকারের Warning message দেখালো তখন সেই সিস্টেমটিকে আমরা Reliable বলতে পারি।
Section 7: Performance Metrics
Throughput
একটি নির্দিষ্ট সময়ের ভিত্তিতে কোনো সিস্টেম যতটুকু কাজ সম্পাদন করতে পারে সেটি হচ্ছে Throughput। যেমন, প্রতি ১০ সেকেন্ড এ সিস্টেম যদি ৫০ টি API request সম্পন্ন করতে পারে তাহলে তার Throughput হবে ৫০/১০ = ৫।
Time to First Byte
ক্লায়েন্ট Resource জন্য যখন সার্ভারকে Request করে এবং ক্লায়েন্ট সার্ভার থেকে FIRST BYTE of Response যখন গ্রহণ করে তার মধ্যকার সময়টুকু (Request করা থেকে শুরু করে এবং FIRST BYTE গ্রহণ করার সময় পর্যন্ত) হল Time to First Byte।
🔗 আরও পড়ুন: পারফরম্যান্স ম্যাট্রিক্স
Section 8: Distributed System
একাধিক কম্পিউটার (বা কম্পোনেন্ট) একসাথে কাজ করার ফলে কোন কাজ শেষ হয় এবং End User এর কাছে একটি কম্পিউটার (বা কম্পোনেন্ট) হিসেবে আসে, সেই সিস্টেমটি হল ডিস্ট্রিবিউটেড সিস্টেম। এই মেশিনগুলোতে শেয়ার্ড স্টেট(Shared State) থাকে, কঙ্কারেন্টলি (Concurrently) কাজ করতে পারে, প্রতিটি সিস্টেম একে অপরের সাথে Information শেয়ার করতে পারবে।
বর্তমান সময়ে Distributed System এর উদাহরণ হল YouTube।
YouTube কেন?
- সার্ভার User থেকে রিকুয়েস্ট পায় Video Upload কিংবা Video Watch করার জন্য।
- ভিডিও এনকোড।
- ডাটাবেস সিস্টেম।
এগুলো সবকিছু মিলে Distributed System YouTube তৈরি করে।
Section 9: Domain Name System
Domain Name System কিংবা DNS একটি নির্দিষ্ট Human Readable Domain (যেমন www.google.com) কে একটি নির্দিষ্ট IP-তে রূপান্তর করে।
আপনি যখন ব্রাউজারে URL টাইপ করেন (যেমন www.google.com)। DNS সাধারণত আপনার দেয়া URL এর IP Address বের করবে এবং সেই IP Address এ আপনার রিকুয়েস্ট প্রসেস হবে।
এই রূপান্তর করার পদ্ধতিটা শুরু হয় DNS Resolver দিয়ে,
-
DNS Resolver মূলত Human Readable Domain কে নির্দিষ্ট IP-তে রূপান্তর করে থাকে। এর ৩টি পার্ট আছে,
-
Root Server, এই সার্ভার মূলত .com, .org, .net ইত্যাদির তথ্য রাখে এবং সেগুলোর IP সেই DNS Resolver কে দিয়ে থাকে যেমন .com এর জন্য .com এর IP, .org এর জন্য .org এর IP
-
Top Level Domain Server, এই সার্ভার মূলত প্রতিটি Top Level Domain (www.google.com এর TLD হল .com) এর Authoritative Server এর তথ্য নিজের মধ্যে রাখে।
- সাধারণ top-level domains: .com, .org, .gov
- দেশীয় code top-level domains: .jp, .uk, .bd
-
Authoritative Server, এই সার্ভারের মধ্যে সেই Human Readable Domain (যেমন www.google.com) এর IP পাওয়া যায়।
-

🔗 আরও পড়ুন: ডোমেইন নেইম সিস্টেম
Section 10: Transmission Control Protocol
Transmission Control Protocol অথবা TCP হচ্ছে একটি নেটওয়ার্ক প্রোটোকল যেখানে একাধিক Device একে অপরের সাথে মেসেজ আদান-প্রধান করতে পারে।
TCP কে Reliable বলা হয় কারণ যতক্ষণ পর্যন্ত ডিভাইসগুলো একে অপরের সাথে মেসেজ অদান-প্রধান শেষ হবে না ততক্ষন connection বন্ধ হবে না।
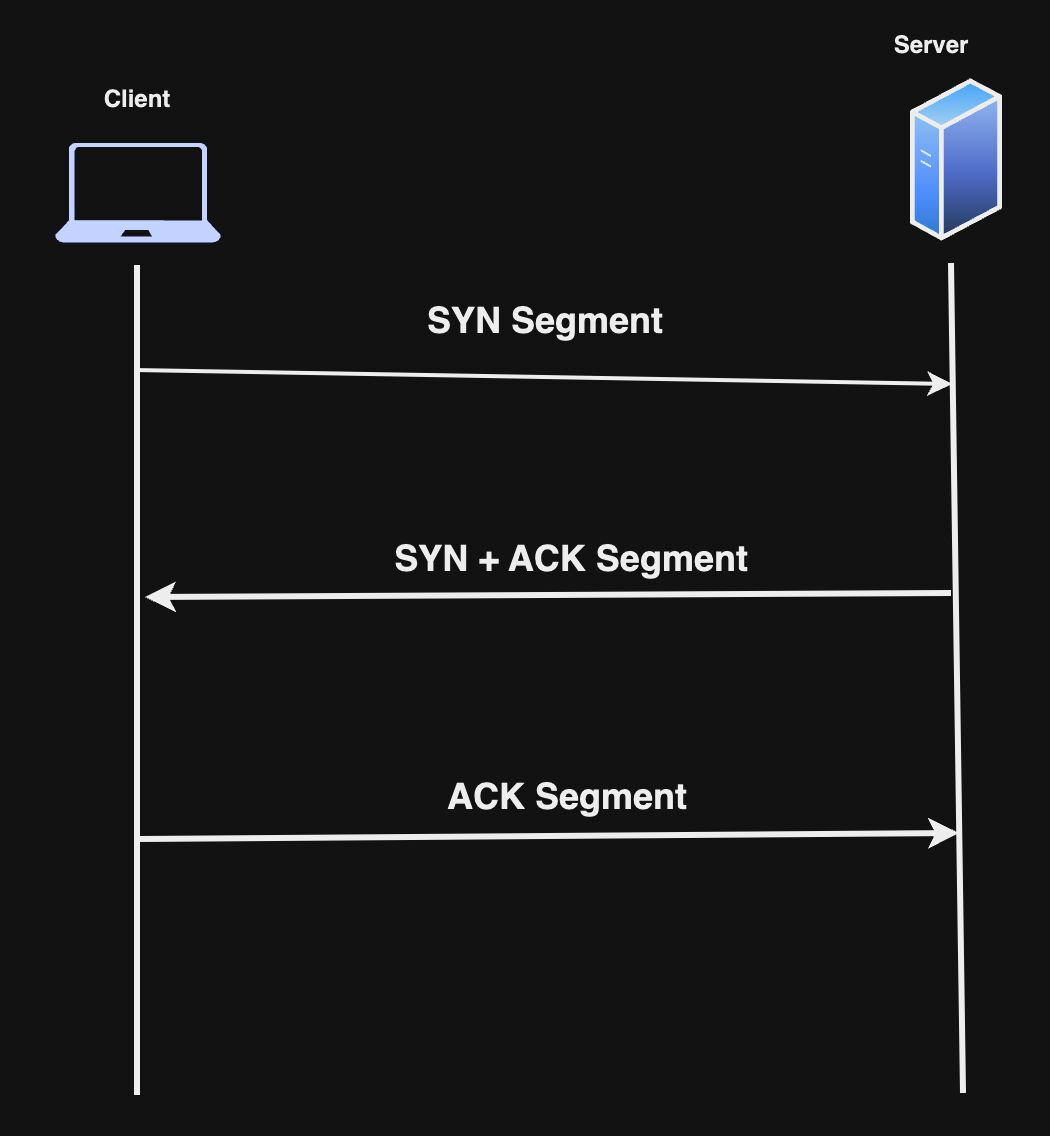
Transmission শুরু হওয়ার পূর্বে TCP 3-way-handshake ব্যবহার করে connection established করে। এটি ৩টি স্টেপে হয়ে থাকে,
- SYN (synchronize): এই flag দ্বারা TCP কানেকশন establish করার রিকোয়েস্ট করা হয়।
- SYN-ACK (synchronize-acknowledge): এই flag কানেকশন establish করতে ব্যবহার করা হয়।
- ACK (acknowledge): এই flag দ্বারা কানেকশন establish সম্পন্ন হওয়ার acknowledge করা হয়।
এই 3-way-handshake নিশ্চিত করে Device’গুলো(ক্লায়েন্ট-সার্ভার) একে অপরের সাথে মেসেজ আদান-প্রধান করতে পারবে কি না।
TCP Reliability নিশ্চিত করে সাধারণত Acknowledgments এবং Retransmissions পদ্ধতি ব্যবহার করে। TCP তে মূলত যখন ক্লায়েন্ট ডেটা send করে সার্ভার রিকোয়েস্ট টি কে Acknowledge করে। ক্লায়েন্ট যদি Acknowledge না পায় তখন ক্লায়েন্ট আবার রিকোয়েস্ট Retransmission করবে। এরকম Reliability নিশ্চিত হয়ে থাকে।
TCP মূলত Networking এর OSI Model এর Practical Form। এটি Transport Layer থেকে শুরু হয় এবং Application Layer এ কাজ করে।
HTTP, Web Socket, FTP ইত্যাদি মূলত TCP তে চলে।
Section 11: User Datagram Protocol
UDP মূলত OSI Model এর Transport Layer-এ অবস্থান করে। TCP এর মত এটি reliable না। এতে কোনো 3-way handshake তৈরী হয় না। এটি মূলত Low Latency এবং unreliable connection তৈরী করে।
UDP Process to Process communication establish করে।
TCP তে যেহেতু 3-way handshake তৈরীর মাধ্যমে reliable connection তৈরী হয়, কিন্তু এই 3-way handshake তৈরী করতে সময়ের প্রয়োজন হয় সেজন্য performance কম পাওয়া যায়। Performance এর কথা বিবেচনা করলে UDP একটি better choice।
UDP তে কোনো Error checking হয় না।
UDP এর use-cases:
- Real-time Communication; উদাহরণ: Skype, Zoom.
- Live Video Streaming; উদাহরণ: Twitch, ESPN+.
- Online Gaming; উদাহরণ: Call of Duty.
UDP লাইভ ভিডিও স্ট্রিমিংয়ের জন্য ব্যবহৃত হয়, কারণ Live ইভেন্টের সাথে সম্প্রচারটি sync রাখা বেশি গুরুত্বপূর্ণ না। UDP ব্যবহার করার সময়, যদি কিছু ফ্রেম হারিয়ে যায়, সেগুলো পুনরায় প্রেরণ করা হয় না। উদাহরণ,
আপনি বিপিএল (ক্রিকেট) দেখছেন। ওভার ১.২-তে হঠাৎ বাফারিং শুরু হলো, আর এখন ওভার ১.৪ চলছে। ওই দুই বল নিয়ে আপনি তেমন চিন্তা করছেন না। আপনি পরের বল দেখছেন। এটি হচ্ছে UDP।
Section 12: HTTP, TLS and HTTPS
HTTP অর্থাৎ Hyper Text Transfer Protocol, HTTP এক প্রকারের বৈশিষ্ট প্রদান করে থাকে, যার মাধ্যমে Web Browser এবং Web Server নিজেদের ভিতর communication করে থাকে। এটি এক প্রকারের set of rules যা ডেটা ক্লায়েন্ট থেকে সার্ভারে পাঠানো সাহায্য করে। ডেটা হতে পারে Text, Image ইত্যাদি। ক্লায়েন্ট এবং সার্ভারের ভিতর ডেটা আদান প্রধান plain-text এ হয়ে থাকে, এর ফলে HTTP secured না।
TLS কিংবা Transport Layer Security, এটি হলো Cryptographic Protocol যা মূলত communication সুরক্ষিত করার জন্য ব্যবহার করা হয়। এটি ডাটা এনক্রিপ্ট করে থাকে ডাটা ক্লায়েন্ট থেকে সার্ভারে ট্রান্সমিট হওয়ার সময়।
HTTPS অর্থাৎ Hyper Text Transfer Protocol Secure, এটি নিজে HTTP এর সকল বৈশিষ্ট বহন করে শুধু SSL/TLS যোগ করে, ক্লায়েন্ট এবং সার্ভারের মধ্যে ডেটা ট্রান্সফার Encrypted হয়ে থাকে।
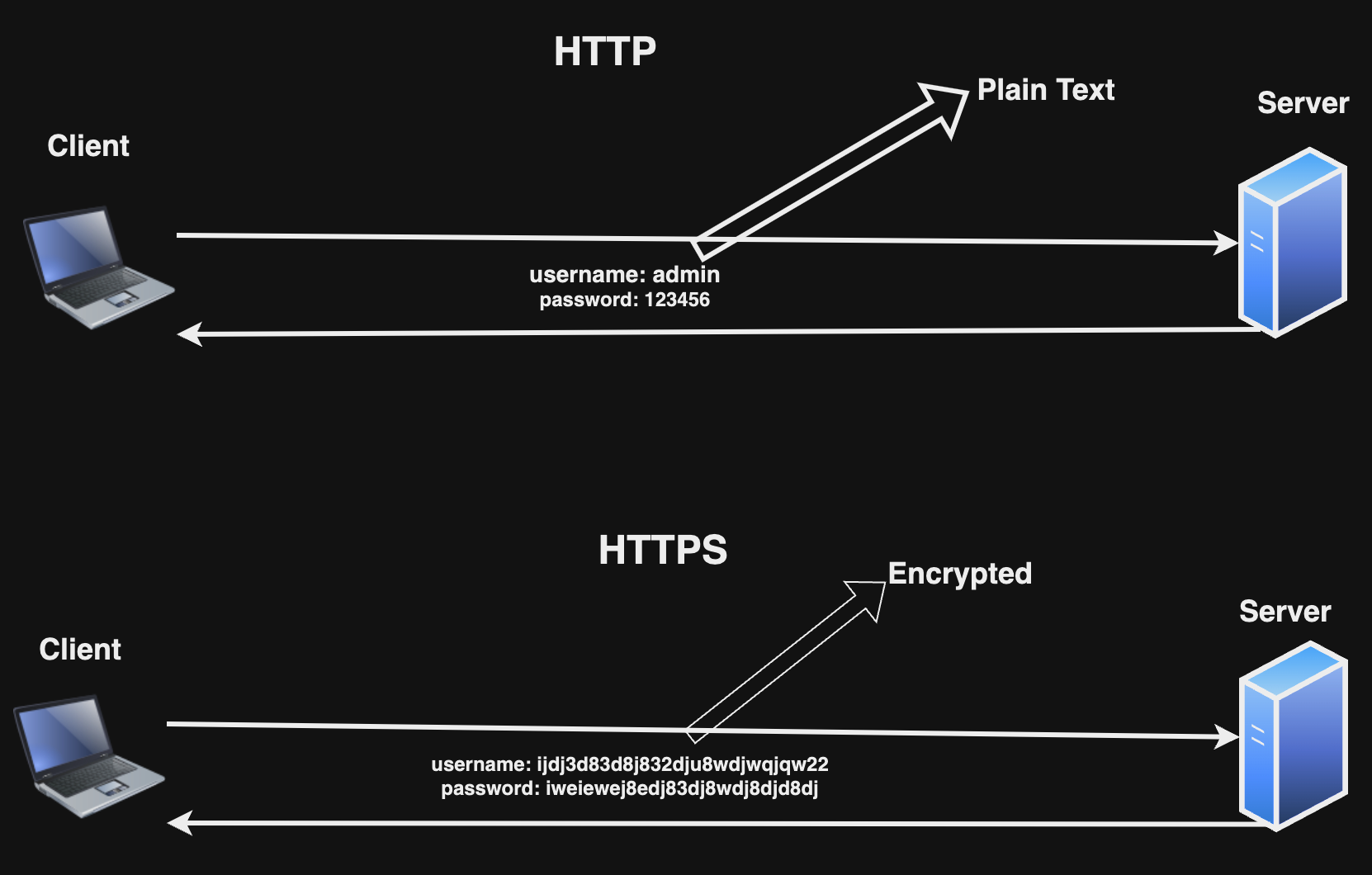
🔗 আরও পড়ুন: এইচটিটিপি, টিএলএস এবং এইচটিটিপি’এস
Section 13: What happens when you type a URL in your browser
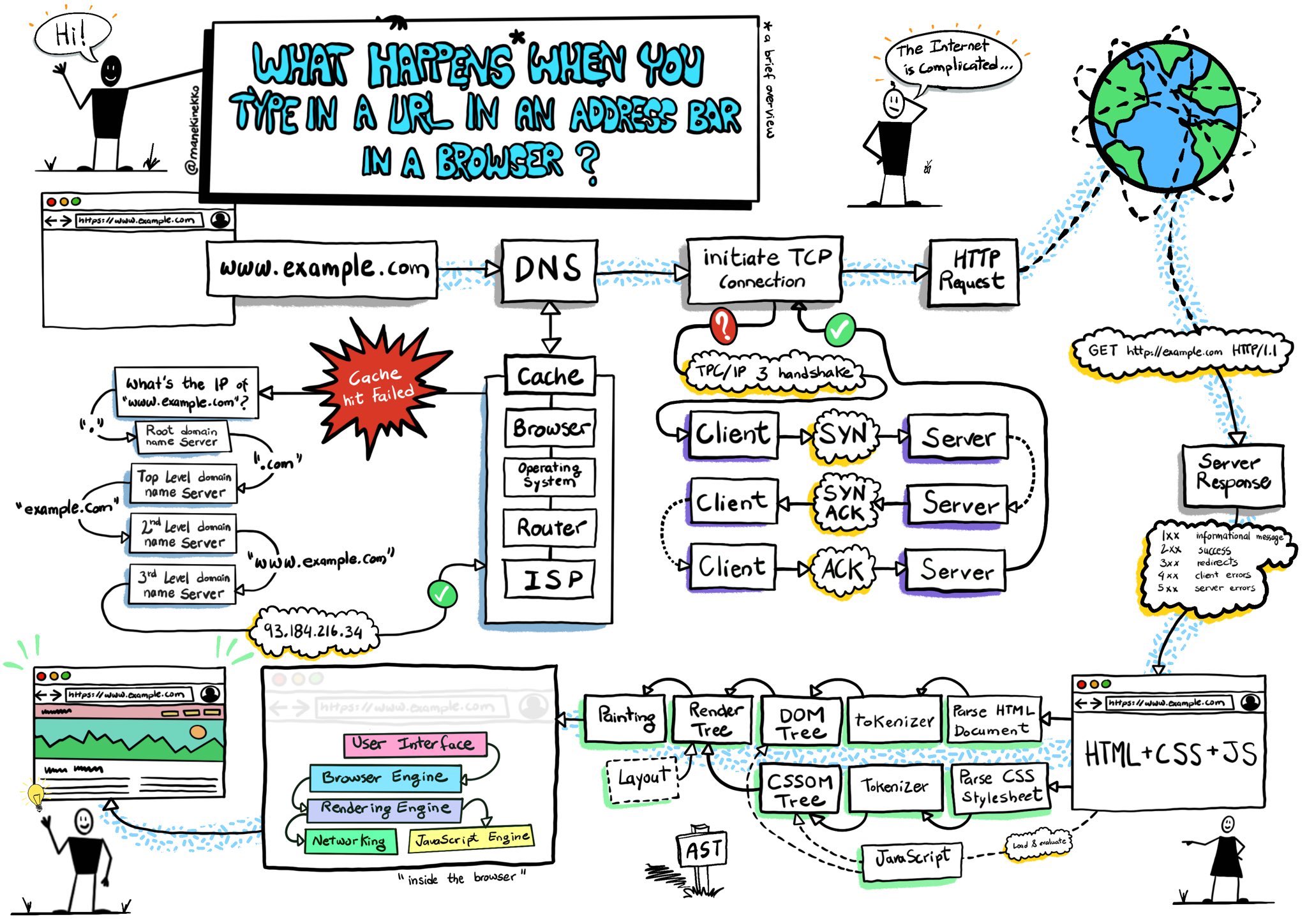
(ছবিটি ইন্টারনেট থেকে ডাউনলোড করা)। আপনি যখন আপনার ব্রাউজার এর Address Bar এ URL টাইপ করে enter press করবেন, আপনার ব্রাউজার প্রথমে আপনার রিকোয়েস্টটিকে DNS সার্ভার এ পাঠিয়ে দিবে তারপর দেখবে DNS cache এর ভিতর সেই URL এর IP এড্রেস আছে কি না। যদি না থাকে তাহলে বিভিন্ন steps শেষ করার পর DNS সেই URL এর IP রিটার্ন করবে।
তারপর 3-way handshake এর মাধ্যমে IP address এর সার্ভার এর সাথে TCP কানেকশন তৈরী হবে।
পরবর্তীতে browser TCP কানেকশন এর সাহায্যে সেই সার্ভারে HTTP রিকোয়েস্ট করে।
সার্ভার রিকোয়েস্ট প্রসেস করে তারপর রেসপন্স রিটার্ন করে থাকে। ব্রাউজার সেই রেসপন্স কে বিভিন্ন স্টেপ শেষ করে ব্রাউজারে দেখায়।
Section 14: Concurrency and Parallelism
Concurrency এবং Parallelism বুঝতে হলে আমাদেরকে Process এবং Thread অপারেটিং সিস্টেম এর আলোকে বুঝতে হবে।
Process কি? একটি প্রোগ্রাম(code) যখন execution অবস্থায় থাকে, তখন সেটি একটি Process। এটি এমন একটি environment বা container, যেখানে প্রোগ্রামের জন্য প্রয়োজনীয় সমস্ত রিসোর্স (যেমন, CPU টাইম, মেমরি) বরাদ্দ করা হয় এবং প্রোগ্রামটি চালানো(execute) হয়।
Thread কি? এটি মূলত Process এর Subset। একে Independent Execution Unit ও বলা হয়। একটি Process-এ এক বা একাধিক Thread থাকতে পারে, Thread মূলত Process এর Shared Resource গুলো ব্যবহার করে থাকে। তার কাজ হচ্ছে প্রোগ্রাম এর অপারেশনগুলোকে Concurrently কিংবা Parallelly(core এর উপর নির্ভর করে) execute করা।
Thread ভালোভাবে বুঝার জন্য Concurrency এবং Parallelism বুঝা যাক।
Concurrency কি? Concurrency হচ্ছে Thread এর মধ্যে একাধিক কাজ থেমে থেমে একসঙ্গে সম্পন্ন হচ্ছে, যদি ১টি CPU কোর থাকে।
ধরুন CPU কোর হচ্ছে ১টি, একাধিক কাজ Thread এর মধ্যে যখন থাকে, তখন Context Switching এর মাধ্যমে CPU দ্রুতভাবে একে অপরকে সময় ভাগ করে, অর্থাৎ একটি কাজ থেমে CPU অন্য কাজ শুরু করে, তারপর আবার সেই কাজ পুনরায় চালু করে যতদূর পূর্বের execution এ সম্পন্ন হয়েছে, তারপরের অংশ থেকে আবার শুরু হয়।
যতক্ষণ না পর্যন্ত সব কাজ শেষ হচ্ছে, এরকম চলতে থাকবে।
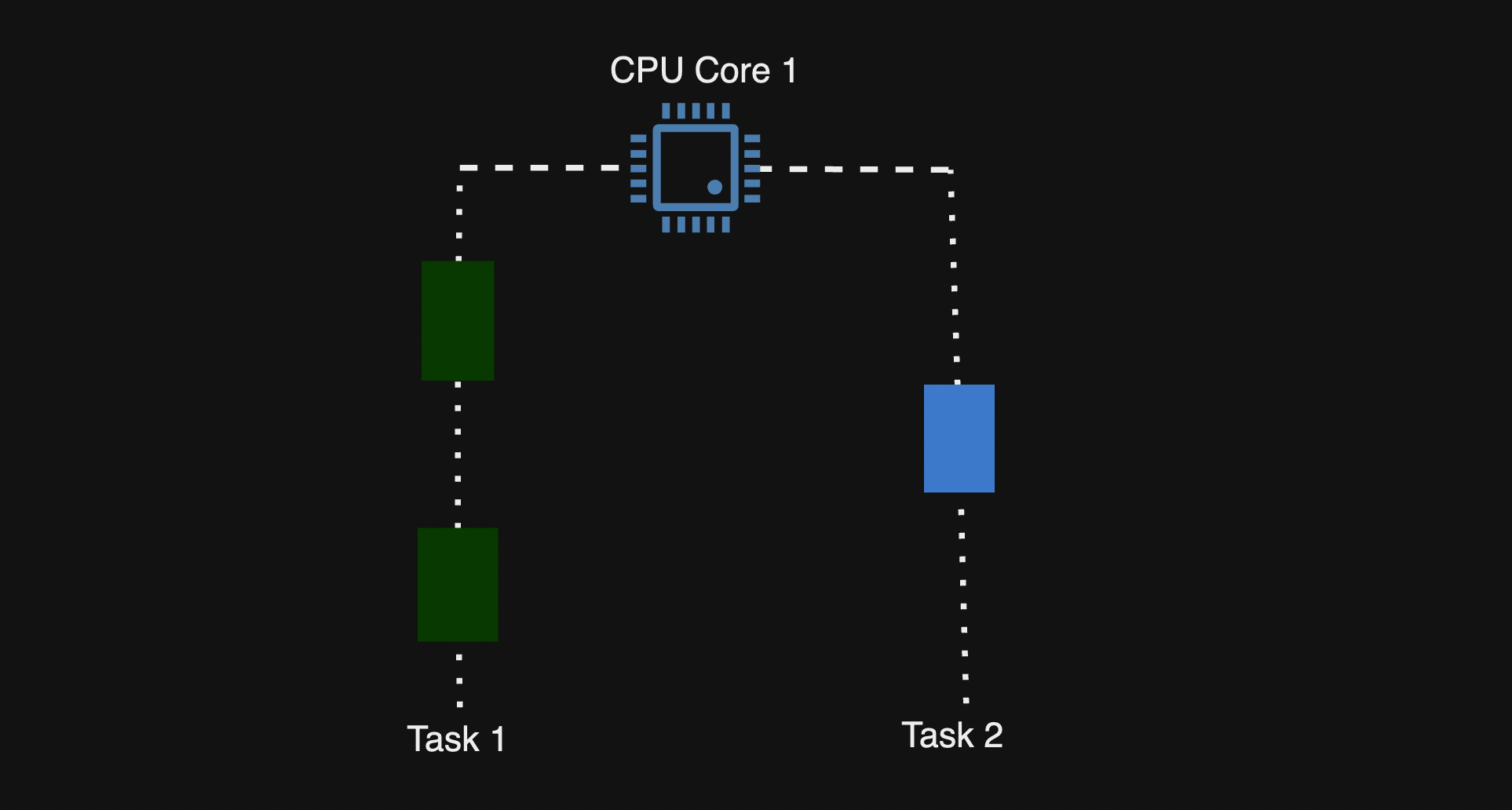
Parallelism কি? একাধিক কাজ একই সময়ে আলাদাভাবে/স্বাধীনভাবে সম্পন্ন করা, এবং এটি সম্ভব যখন একাধিক CPU core থাকে।
ধরুন CPU কোর হচ্ছে ২টি, একাধিক কাজ Thread গুলোর মধ্যে execute হবে।

একাধিক কোর এর মধ্যেও Concurrency হয়ে থাকে। কখন?
যখন সব Thread ব্যস্ত হয়ে পড়বে তখন অন্য Task গুলোর জন্য Context Switching এর মাধ্যমে Task গুলো সম্পাদন করা হবে।
বাস্তব জীবনের উদাহরণ,
একজন waiter:
- এক table থেকে order নেয়
- kitchen এ দিয়ে আসে
- অন্য table এ যায়
এটা concurrency
কিন্তু waiter একা, parallel না
দুইজন waiter:
- একই সময়ে দুই table serve করছে
এটা parallelism
Concurrency উদাহরণ I/O bound task এর জন্য Node.js দিয়ে,
const fetch = require("node-fetch");
async function fetchData() {
const urls = [
"https://jsonplaceholder.typicode.com/posts/1",
"https://jsonplaceholder.typicode.com/posts/2",
"https://jsonplaceholder.typicode.com/posts/3",
];
const promises = urls.map((url) => fetch(url).then((res) => res.json()));
const results = await Promise.all(promises);
console.log(results);
}
fetchData();
Node.js Parallel Execution এর জন্য Worker Threads, Child Processes, Cluster module রয়েছে।
🔗 আরও পড়ুন: কনকারেন্সি এবং পেরালেলিসম
Section 15: High Concurrency Control
High Concurrency মানে হচ্ছে, যখন একাধিক user কিংবা একাধিক process একই সময়/একই মুহূর্তে একটি নির্দিষ্ট রিসোর্স কিংবা একটি নির্দিষ্ট ডাটা modify করতে যায়। এর দ্বারা অনেক সমস্যা সৃষ্টি হতে পারে, যার মধ্যে সবচেয়ে গুরুত্বপূর্ণ সমস্যা হচ্ছে Data Inconsistency।
(চলমান)
Section 16: Functional and Non Functional Requirements
Functional Requirements
একটি সিস্টেম কি কি কাজ করে সেটি Functional Requirement উল্লেখ করে থাকে। উদাহরণ বলা যায়, সোশ্যাল মিডিয়া সিস্টেমে,
- পোস্ট করা যায়
- পোস্টে লাইক করা যায়
- পোস্টে কমেন্ট করা যায়
- পোস্টে ডিলিট করা যায়
প্রতিটা হচ্ছে এক একটি Functional Requirement।
Non Functional Requirements
এটি মূলত একটি সিস্টেমের গুণমান বৈশিষ্ট্যতা (Quality Characteristics), উদাহরণ:
- Performance
- Security
- Cost
- Scalability
- Reliability
প্রতিটা হচ্ছে এক একটি Non Functional Requirement।
Section 17: Back Of the Envelope Estimation
এটি একটি টেকনিক যা আমাদেরকে সিস্টেম ডিজাইন এর Load Balancer, CDN ইত্যাদি ব্যবহার করবো কি না তার আনুমানিক ধারনা হিসাব করে বলে দিতে পারে।
🔗 আরও পড়ুন: ব্যাক অফ দা এনভেলপ এস্টিমেশন
Section 18: Authentication and Authorization
একটি secured সিস্টেম design করতে হলে Authentication এবং Authorization জানা অত্যন্ত গুরুত্বপূর্ণ। Authentication মূলত identity verify করাকে বুজায়। আমরা যখন কোনো সিস্টেমে গিয়ে ইমেইল এবং পাসওয়ার্ড দিয়ে লগইন করার চেষ্টা করি, সেই ইমেইল আর পাসওয়ার্ড ভেরিফাই করে হচ্ছে Authentication।
Authorization হলো কোনো নির্দিষ্ট রিসোর্সে নির্দিষ্ট user এক্সেস করতে পারবে কি না তা বুঝায়। যেমন কোনো এপ্লিকেশন এ নির্দিষ্ট API থাকে যা শুধুমাত্ৰ এডমিনিস্ট্রেটর মানুষ ছাড়া ব্যবহার করতে পারবে না, এখন যদি কেউ এক্সেস করতে চায় তাহলে সেই মানুষটা Authorize আছে কি না সেটাই যাচাই করা হচ্ছে Authorization।
🔗 আরও পড়ুন: অথেনটিকেশন এবং অথরিজাশন
Section 19: Stateful and Stateless Architecture
Stateful
এই আর্কিটেকচারে ডেটা Store এবং Maintain Application সার্ভারে হয়ে থাকে। FTTP হল Stateful।
বাস্তব জীবনে Stateful আর্কিটেকচার এর উদাহরণ হল Web Socket। Web Socket মূলত bidirectional, full-duplex protocol। এখানে Server ডেটা store করে রাখে, যাতে Client সবসময় Server থেকে ডেটা পায়।
Stateless
এই আর্কিটেকচারে ডেটা Store এবং Maintain Application সার্ভারে হয় না বরং কোনো Database বা Cache এ স্টোর এবং মেইনটেইন হয়। HTTP হল Stateless।
HTTP সবসময় Stateless Architecture, কারণ কোনো protected resource এর জন্য আপনাকে সবসময় request করার সময় cookie/token সাথে দিতে হয়। server কখনো cookie/token স্টোর করে রাখে না।
🔗 আরও পড়ুন: স্টেটলেস-স্টেটফুল আর্কিটেকচার
Section 20: Proxy
ক্লায়েন্ট যখন সার্ভারকে রিকুয়েস্ট পাঠানোর সময় সরাসরি সার্ভারকে রিকুয়েস্ট না করে অন্য একটি সার্ভাররের মাধ্যমে রিকুয়েস্ট করলে, সেই প্রসেস হচ্ছে প্রক্সি এবং যে সার্ভার দিয়ে রিকুয়েস্ট করবে সেটা হচ্ছে প্রক্সি সার্ভার।
বাস্তব জীবনে প্রক্সির একটি উদাহরণ হচ্ছে NGINX।
Section 21: REST Api
REST Api জানার পূর্বে আমাদের বুঝতে হবে রেস্ট(REST) মানে কি, REST মানে হল Representational State Transfer যার মানে দাড়ায় এটি একটি আর্কিটেকচারাল স্টাইল যা ব্যবহার করা হয় স্টেট ট্রান্সফার এর জন্য। এখন REST Api হল, এক প্রকারের এপিআই কনভেনশন যা ব্যবহার করা হয় দুটি এন্ড(যেমনঃ ক্লায়েন্ট এবং সার্ভার) এর মধ্যে স্টেট ট্রান্সফার করাকে নিশ্চিত করার জন্য।
স্টেট ট্রান্সফার নিশ্চিত করতে কিছু স্পেসিফিক HTTP Methods ব্যবহার করা হয়, GET, POST, PUT, PATCH & DELETE, প্রতিটি ম্যাথোডের ব্যবহার জানতে REST Api সেকশনে ক্লিক করুন।
Section 22: Scalability
স্কেলেবিলিটি সাধারণত সিস্টেমের ক্ষমতাকে বুঝায় যখন সিস্টেমে ট্রাফিকের পরিমাণ বাড়তে থাকে। উদাহরণ বলা যেতে পারে, একটি ওয়েবসাইটের ডাটাবেসে এখন একটি নির্দিষ্ট পরিমাণ রিকুয়েস্ট করা হচ্ছে কিন্তু আজ থেকে ৫ মাস পর রিকুয়েস্ট ২ গুণ হয়ে গেল তার ঠিক আরও ৫ মাস পর রিকুয়েস্ট ৪ গুণ হয়ে গেল, একটা সময় দেখা যেতে পারে ডাটাবেস সার্ভার এত পরিমাণ রিকুয়েস্ট লোড নিতে পারছে না, এই সমস্যার সমাধানের জন্য স্কেল করাকে স্কেলেবিলিটি বলে।
স্কেলেবিলিটি সাধারণত 2 প্রকারের, ভার্টিকাল স্কেলেবিলিটি (Vertical Scalability) এবং হরাইজন্টাল স্কেলেবিলিটি (Horizontal Scalability)।
Section 23: Database Sharding
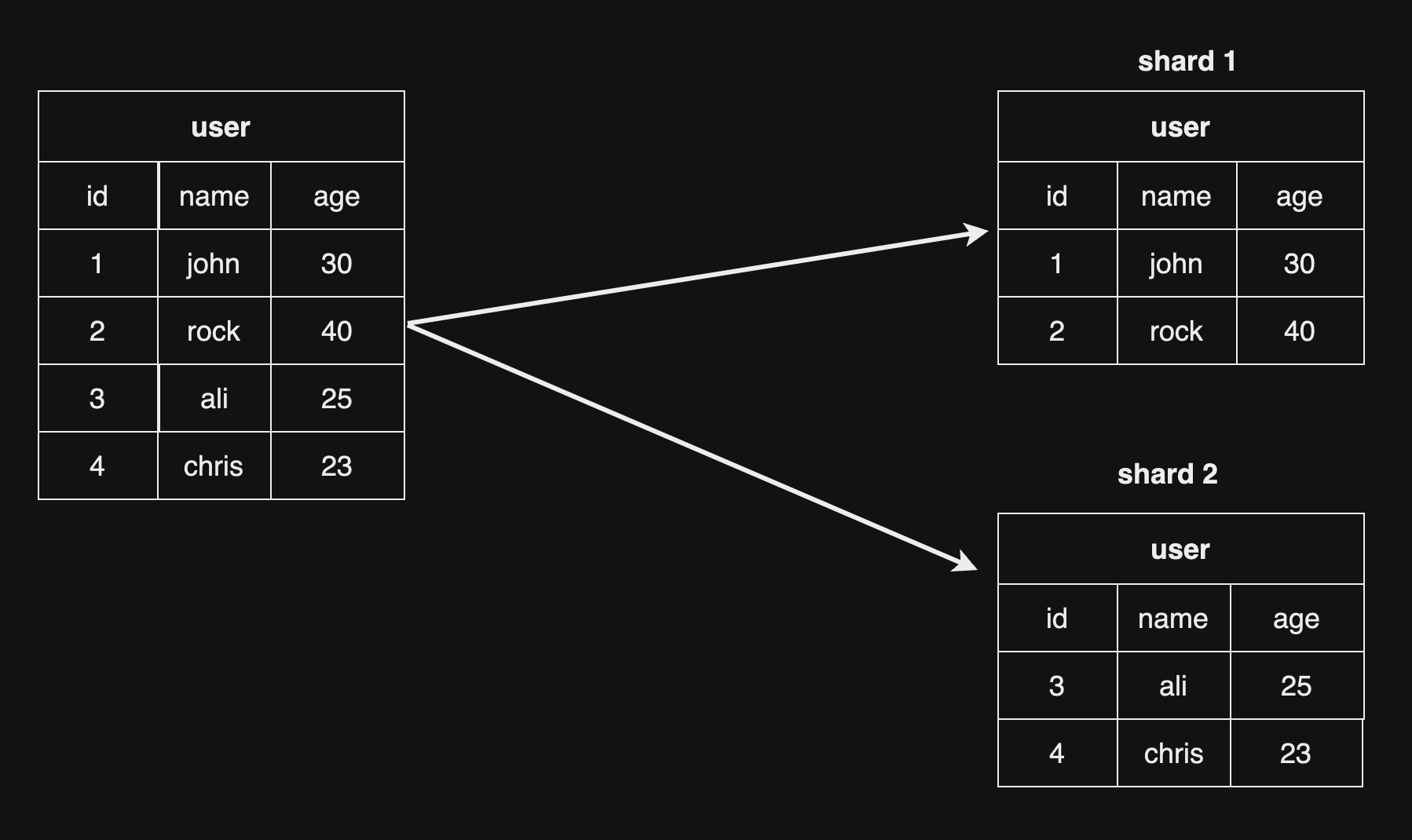
Database Sharding হল টেবিল থেকে ডেটা পৃথক করা। উদাহরণ বলা যায়, ডাটাবেসের ডেটা/row যদি বাড়তে থাকে এবং এত পরিমাণ ডেটা/row বেড়ে গেল যার ফলে ডাটাবেস টেবিলে আর স্টোর করা যায় না তখন আমরা ডেটাগুলোকে মূল টেবিল থেকে পৃথক করে অন্যান্য shard টেবিলে distribute করে রাখি সেটাই Database Sharding। একাধিক সার্ভার এই ডিস্ট্রিবিউশন হবে।
Section 24: Database Replication
Database Replication এক প্রকারের Strategy, যেখানে একটি Master Database এবং একটি কিংবা একাধিক Slave Database থাকবে। Master Database এর মধ্যে Insert, Delete এবং Update এর কাজ হবে এবং Slave Database মধ্যে Master Database এর ডেটাগুলোর Copy থাকবে এবং তার মধ্যে শুধু Read Operation হবে।
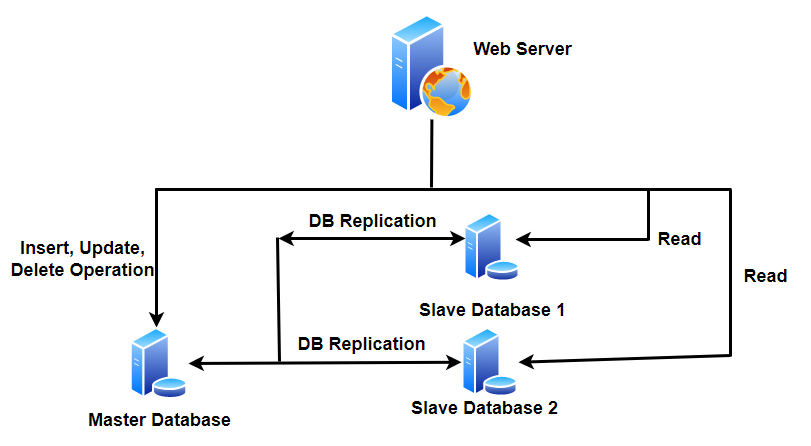
Database Replication, SQL এবং NoSQL দুটি ডেটাবেসে করা যায়।
🔗 আরও পড়ুন: ডেটাবেস রেপ্লিকেশন
Section 25: Caching
Caching একটি কৌশল যা দ্বারা কোন Expensive Response’কে কোনো মেমোরিতে রাখা হয়, যাতে বার বার আসা সেই রেস্পন্সের রিকোয়েস্ট কে দ্রুত রেসপন্সটি দিতে পারি। মূল সার্ভারে (যেমন ডাটাবেস) হিট করার পরিবর্তে ক্যাশিং সার্ভারে রিকোয়েস্ট করবে। এতে করে যে সুবিধাটুকু হবে,
- Read API রিকোয়েস্ট Fast হবে
- Latency Reduce হবে
- Fault Tolarence এর ঝুঁকি কমবে
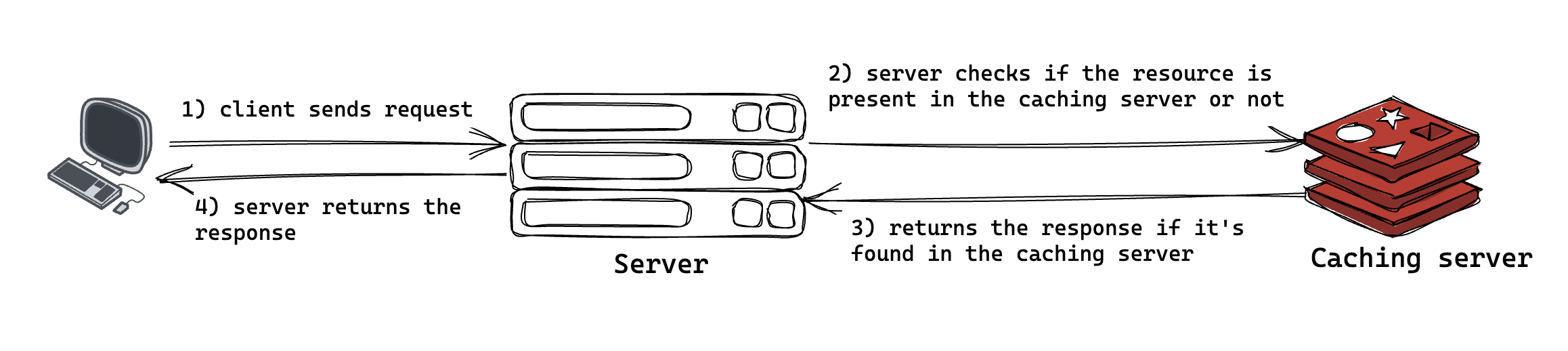
Section 26: Content Delivery Network
Content Delivery Network অথবা CDN, এটি একটি সিস্টেম যেখানে একাধিক সার্ভার আমাদের ভৌগোলিক এর আসেপাশে থাকে, যাতে আমরা খুব দ্রুত কন্টেন্ট পেতে পারি। কন্টেন্টটি হতে পারে JS, CSS, Images কিংবা Videos।
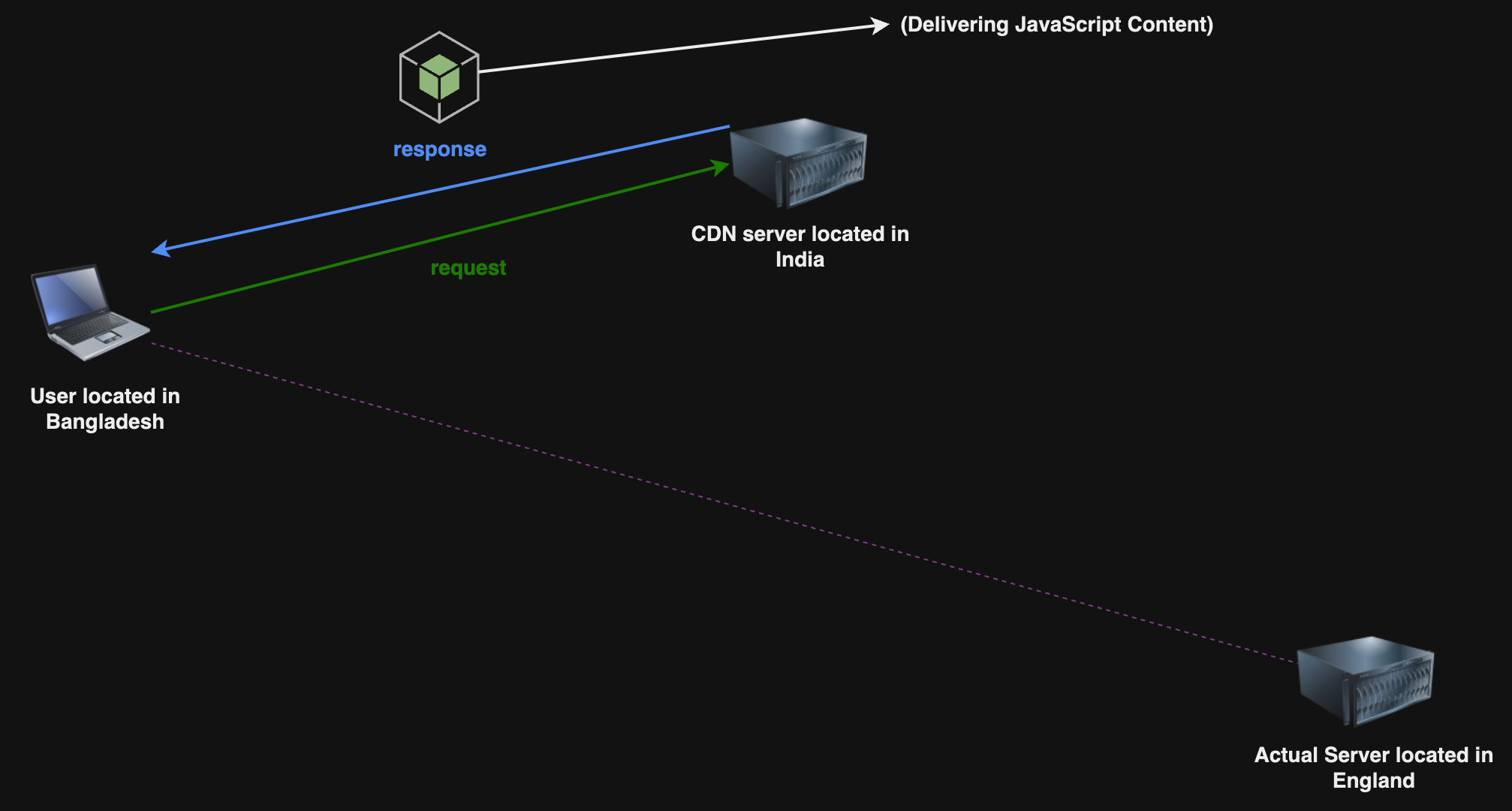
আমাদের CDN সার্ভার যদি India তে থাকে আর আমরা Bangladesh থেকে content request করি তাহলে খুব তাড়াতাড়ি content পাব। কারণ তখন Latency কমে যাবে। আর আমরা Bangladesh থেকে England-এ যেখানে মূল সার্ভার আছে, সেখানে কনটেন্ট এর জন্য request করলে Latency স্বাভাবিকভাবে বৃদ্ধি পাবে, যেহেতু দুই দেশের দূরত্ব বেশি।
যে যে লোকেশনে CDN সার্ভার আছে সেই লোকেশনগুলোকে Point of Presence বা PoP বলে। যে সার্ভার PoP এর ভিতরে থাকে তাকে Edge Server বলে।
🔗 আরও পড়ুন: কনটেন্ট ডেলিভারি নেটওয়ার্ক
Section 27: Rate Limiter
Rate Limiter একটি প্রসেস, যেখানে ক্লায়েন্ট থেকে আসা রিকোয়েস্ট সার্ভারে যাওয়ার পূর্বে রিকোয়েস্টটি কন্ট্রোল করা হয়। একটি নির্দিষ্ট সময়ের মধ্যে একটি নির্দিষ্ট পরিমাণ রিকোয়েস্ট Rate Limiter এর মাধ্যমে সার্ভার রিকোয়েস্ট গ্রহণ করে থাকে। নির্দিষ্ট পরিমানের চেয়ে রিকোয়েস্ট বেশি হয়ে গেলে Rate Limiter রিকোয়েস্টগুলোকে block করে ফেলে, যার ফলে রিকোয়েস্টগুলো আর সার্ভারে যেতে পারে না।
এখানে মূল পয়েন্ট ২টি, নির্দিষ্ট সময় এবং নির্দিষ্ট পরিমাণ রিকোয়েস্ট।
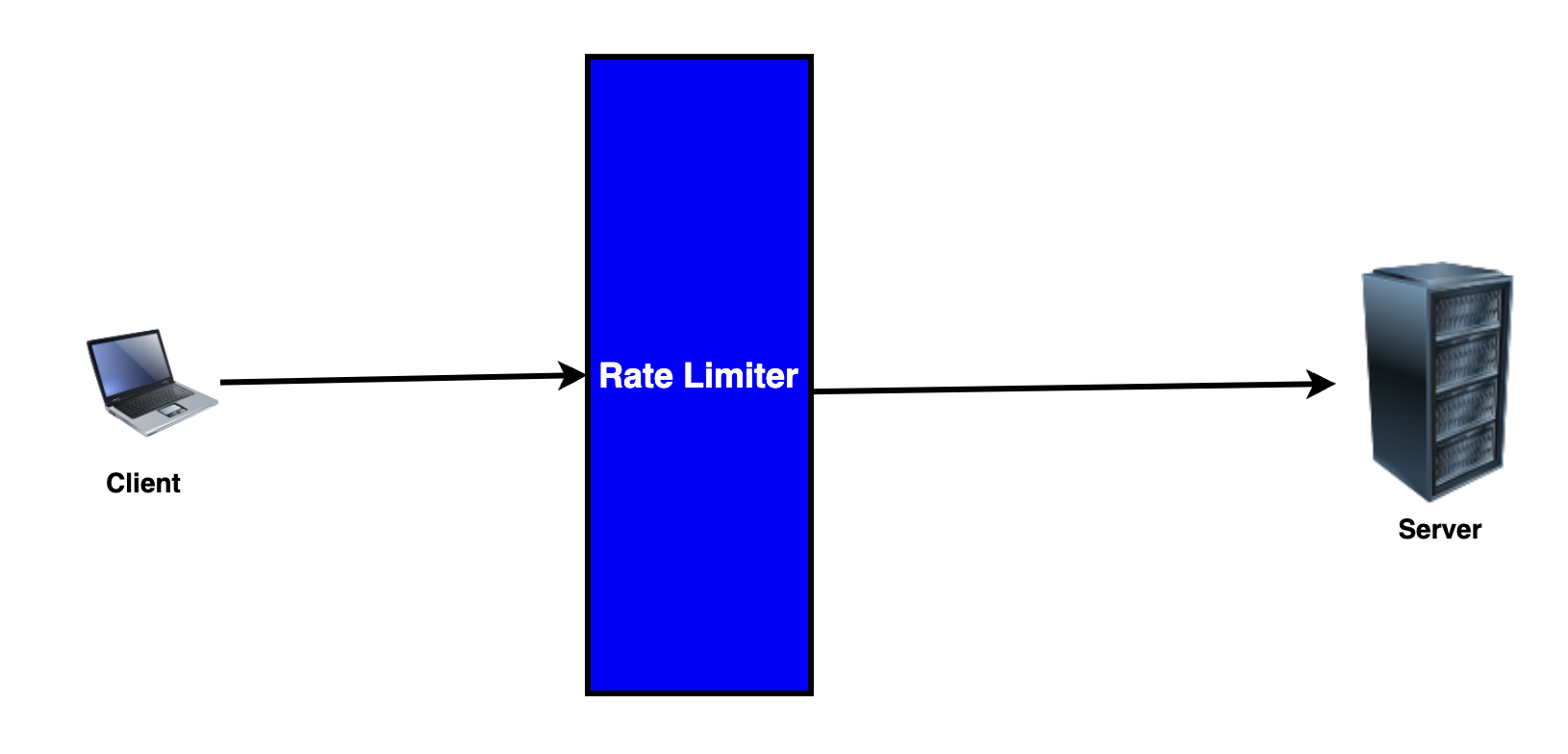
উপরের ছবিতে দেখা যাচ্ছে, রিকোয়েস্ট এবং রেস্পন্সের মধ্যে middleware হিসেবে rate limiter আছে।
Section 28: CAP Theorem
এটি একটি কনসেপ্ট বা থিওরি যা দ্বারা বুজা যায়, একটি Distributed System এ উল্লিখিত তিনটি প্রোপার্টি থেকে দুইটি প্রোপার্টি সবসময় মেনে চলবে।
- C মানে Consistency
- A মানে Availability
- P মানে Partition Tolerance
Consistency হচ্ছে একটি ট্রান্সেকশন (Transection) শেষ হওয়ার পর সব নোডে সবসময় consistent বা একই value থাকবে।
Availability মানে হচ্ছে প্রতিটি read এবং write রিকোয়েস্ট হয় প্রসেস(process) হবে না হয় কোনো message পাবে যে অপারেশন(request) প্রসেস(process) হচ্ছে না।
Partition Tolerance হচ্ছে একাধিক নোড একে অপরের সাথে কানেকশন(connection) নষ্ট হলেও, read এবং write অপারেশন ঠিকভাবে প্রসেস হবে।
Section 30: Polling, Web Socket, Server-Sent Events and Webhooks
Polling মানে হচ্ছে client regular interval এ server কে বার বার ডেটার জন্য রিকোয়েস্ট করবে। যেমন, ক্লায়েন্ট প্রতি ৫ সেকেন্ড পর পর সার্ভার কে রিকোয়েস্ট করবে আর সার্ভার তার রেসপন্স দিবে।

Polling এর সবচেয়ে বড় সমস্যা হচ্ছে অতিরিক্ত Bandwidth ব্যবহার হওয়া।
Web Socket মানে হচ্ছে Socket এর মাধ্যমে সার্ভার এবং ক্লায়েন্ট এর মধ্যে একটি কানেকশন তৈরী হবে যা ক্লায়েন্ট বা সার্ভার যতক্ষন পর্যন্ত disconnected না হচ্ছে ততক্ষন পর্যন্ত কানেকশন থাকবে। ক্লায়েন্ট এখানে সার্ভারকে বার বার রিকোয়েস্ট করা লাগবে না, যেহেতু কানেকশন আছে ক্লায়েন্ট এবং সার্ভার এর মধ্যে সেহেতু কোনো প্রকারের event সার্ভারে সংঘটিত হলে সার্ভার এর রেসপন্স ক্লায়েন্টকে পাঠিয়ে দিবে। Web Socket টেকনোলজি ব্যবহার করে Chat Application বানানো যায়।

Web Socket এ সার্ভার এবং ক্লায়েন্টের মধ্যে একটি কানেকশন তৈরী হয়, অর্থাৎ সার্ভারের ভিতর ক্লায়েন্টের কিছু ইনফরমেশন থাকতে হবে যাতে সার্ভার ক্লায়েন্টকে ট্র্যাক করতে পারে। এজন্য এটিকে Stateful Architecture বলা হয়।
🔗 আরও পড়ুন: পোলিং, ওয়েব সকেট এবং সার্ভার সেন্ট ইভেন্টস
Section 32: Message Queue
এটি একটি প্রসেস যেখানে এক বা একাধিক Producer থাকবে, যাদের কাজ হচ্ছে Message - Queue এর মধ্যে send করা এবং queue সেই রিকোয়েস্টগুলোকে প্রসেস করে বিভিন্ন consumer এর কাছে পাঠিয়ে দেয়।

সিস্টেমের Throughput বৃদ্ধি করার জন্য Message Queue ব্যবহার করা হয়।
Message Queue প্রতিটা Task কে Asynchronously প্রসেস করে থাকে, মানে একটি Task প্রসেস হয় তখন অন্য task এর উপর নির্ভর করে না।
পপুলার Streaming Service Netflix, Airbnb ইত্যাদি Message Queue ব্যবহার করে। Agoda তাদের Analytical Data, Real-time Monitoring এর Solution এর জন্য Message Queue ব্যবহার করে আসছে, 1.8 trillion events প্রতি দিন Message Queue এর মাধ্যমে প্রসেস করে আসছে।
আমরা যে কোনো Food Delivery সিস্টেমের কথা চিন্তা করি যদি, যেখানে একজন Delivery boy এর লাইভ লোকেশন আমরা যদি Pooling এর মাধ্যমে ৫ সেকেন্ড পর পর নিয়ে থাকি এবং কোন সময়ে কোন লোকেশনে ছিল সেটি ডাটাবেসের মধ্যে স্টোর করে রাখি। একজন ইউজার এর জন্য চিন্তা করলে আমাদের সিস্টেম ঠিকমতো কাজ করবে, ডাটাবেস স্টোর করে রাখবে।
কিন্তু আমাদের সিস্টেম একজন মানুষ ব্যবহার করবে না। হাজার হাজার Delivery boy এর লাইভ লোকেশন আমরা যদি সরাসরি ডাটাবেসে স্টোরে করে রাখি, তাহলে আমাদের সিস্টেম ক্র্যাশ করবে। কারণ ডাটাবেসের Throughput কম।
এই সমস্যার সমাধান আমরা Message Queue এর মাধ্যমে করতে পারব। ২ টি জনপ্রিয় Message Queue হচ্ছে,
- Kafka
- RabbitMQ
Section 34: Single Sign-On
Single Sign-On কিংবা SSO হল একটি Authentication Mechanism। যা user কে একাধিক প্লাটফর্ম (গুগল, ফেইসবুক, টুইটার) দিয়ে Authenticate করে দেয়, একটি নির্দিষ্ট credential মাধ্যমে।
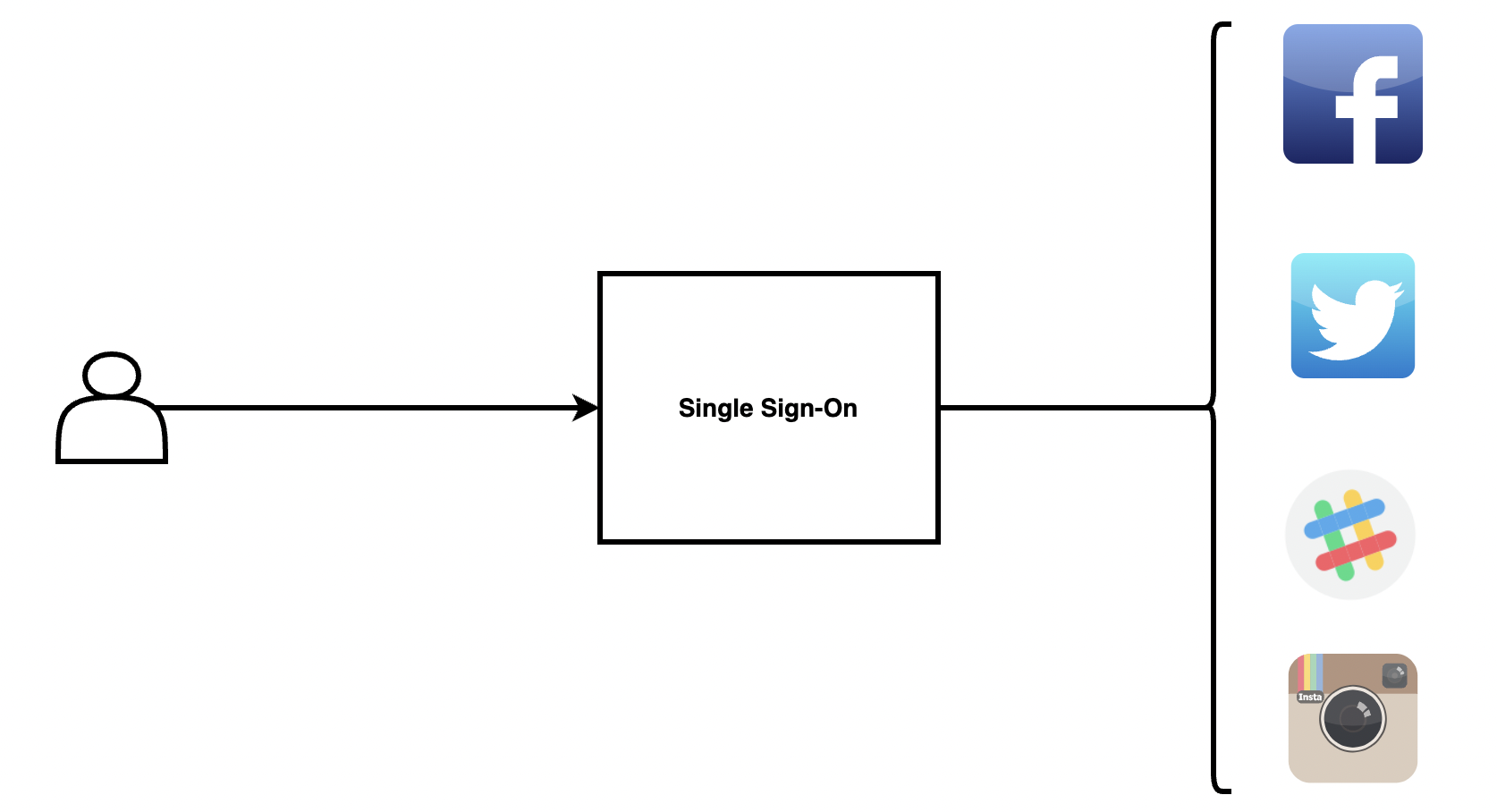
(বিস্তারিত চলমান)
Section 35: Elasticsearch
এটি একটি NoSQL ভিত্তিক ডেটাবেস। মূলত এটিকে Distributed Search এবং Aggregation Engine হিসেবে ব্যবহার করা হয়। Elasticsearch এর ভিতর structured এবং unstructured data স্টোর করে রাখা যায়।
Section 36: Bloom Filter
Bloom Filter একটি Probabilistic Data Structure। Hashing টেকনিক ব্যবহার করে এখানে ডেটা insert করা হয়। এটি খুবই Faster এবং মেমোরি Efficient।
Bloom Filter এর ব্যাপারে জানার পূর্বে Hashing কি জানা নেয়া যাক। একটি Hash Function নিজের প্যারামিটারে input নিয়ে থাকে এবং সেই input কে প্রসেস করে একটি ফিক্সড length এর unique identifier রিটার্ন করে।
উদাহরণ, ইনপুট ‘david’ হলে আউটপুট হবে 5
// hash function
function generateHash(table_size, user) {
let index;
let user_length = user.length;
index = user_length % table_size;
return index;
}
generateHash(10, "david"); // 5
Bloom Filter Data Structure এ Hash function ব্যবহার করে আমরা set এর মধ্যে specific position এ element insert করতে পারি। তারপর set এর মধ্যে specific element সার্চ করতে পারি।
এর মধ্যে যখন আমরা নির্দিষ্ট element সার্চ করি তখন আমরা দুটি জিনিসের মধ্যে একটি পাবো,
-
হয় possibly yes - মানে element, set এর মধ্যে থাকবে তবে না থাকার সামান্য কিছু সম্ভাবনা আছে।
-
না হয় no - মানে element, set এর মধ্যে নাই।
এজন্য তাকে Probabilistic Data Structure বলা হয়।
Section 38: How OAuth2 works
OAuth2 হল এক প্রকারের Authorization Grant Technique। এটি Google, Facebook এর মত ওয়েবসাইট থেকে নির্দিষ্ট information আনতে পারে কোনো প্রকারের password এবং অন্যান্য sensitive information ছাড়া। এই নির্দিষ্ট information এ একটি Access Token থাকে যা দ্বারা আমরা নির্দিষ্ট রিসোর্স(হতে পারে কোনো ওয়েবসাইট এ Login) ব্যবহার করতে পারবো।
এটি যেভাবে কাজ করে,
ধরুন আপনি কোনো ওয়েবসাইটে লগইন করছেন। সেজন্য আপনি Continue with Google বাটন ক্লিক করলেন,
-
প্রথমে ওয়েবসাইট (মানে ক্লায়েন্ট) Google-এর Authorization Server-এ একটি Authorization Request পাঠায়।
-
Google ইউজারকে তার লগইন পেজে রিডাইরেক্ট করে, যেখানে সে Email ও Password Google-এর পেইজে ইনপুট দেয়।
-
ইউজার যদি সফলভাবে লগইন করে এবং পারমিশন দেয়, তখন Google ক্লায়েন্টকে একটি Authorization Code পাঠায়।
-
ক্লায়েন্ট সার্ভার এই Authorization Code ব্যবহার করে Google-এর Authorization Server-এ একটি Access Token এর জন্য রিকোয়েস্ট পাঠায়।
-
Google একটি Access Token (এবং সম্ভব হলে ID Token) পাঠায় ক্লায়েন্ট সার্ভারকে।
-
এরপর ক্লায়েন্ট এই Access Token ব্যবহার করে Google-এর Resource Server থেকে ইউজারের তথ্য (যেমন নাম, ইমেইল) সংগ্রহ করতে পারে।
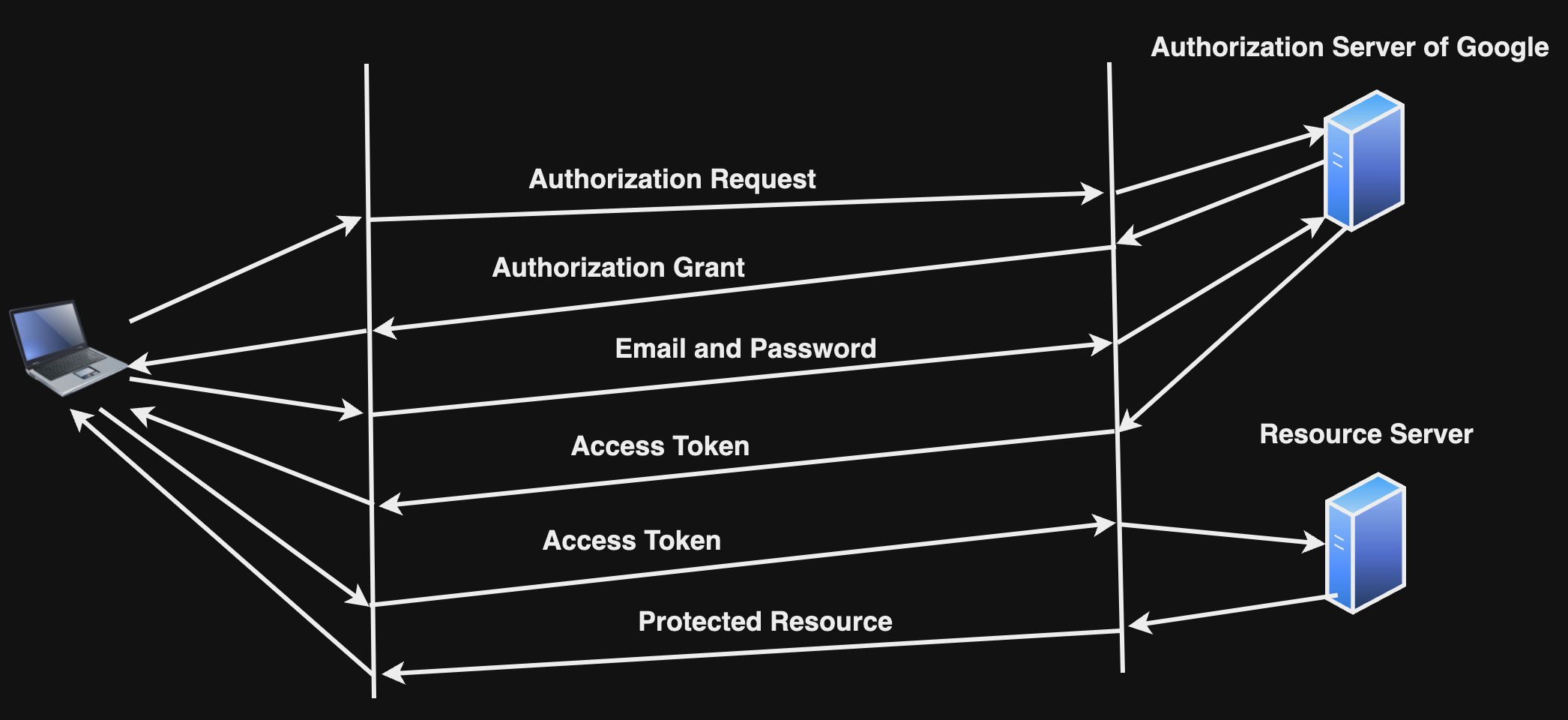
Section 41: How to choose the right database for your application
খুবই গুরুত্বপূর্ণ একটি বিষয়। আমাদের এপ্লিকেশন এর বৈশিষ্ট এর নির্ভর করে, সঠিক ডাটাবেস নির্বাচন করতে হবে।
- ডাটার গঠন: কিছু ডাটাবেস আছে যেগুলোতে ডাটা রাখার আগেই সব কিছু ঠিক করে দিতে হয় — কোন কোন কলাম থাকবে, সেই কলামে কী ধরনের তথ্য রাখা যাবে। এটাকেই বলে Predefined Schema। এসব ক্ষেত্রে Relational Database (SQL) বেছে নেওয়াই ভালো। যেমন — MySQL, PostgreSQL।
আর যদি ডাটার গঠন নিয়ে এখনো নিশ্চিত না হন, বা ভবিষ্যতে নতুন তথ্য যোগ করার বা বাদ দেওয়ার সম্ভাবনা থাকে, তাহলে Non-Relational Database (NoSQL) বেশি সুবিধাজনক। এই ধরনের ডাটাবেসে ডাটা অনেকটা ডকুমেন্টের মতো করে সাজানো থাকে, আগে থেকে কোনো কাঠামো ঠিক করে দেওয়ার দরকার হয় না। যেমন — MongoDB।
যদি আপনার এমন কিছু দরকার হয় যা খুব কম latency-তে (মিলিসেকেন্ড বা তারও কম সময়ে) লোড হতে হবে—যেমন ইউজারের লগইন সেশন, শপিং কার্ট, বা সাময়িকভাবে কোনো ডেটা ক্যাশ করে রাখা; তাহলে Key-Value database বেশি সুবিধাজনক। যেমন — Redis।
যদি আপনার ডাটার মধ্যে connection বা relationship খুব গুরুত্বপূর্ণ হয় (যেমন — কে কাকে follow করে, কার সাথে কার সম্পর্ক, recommendation system ইত্যাদি); তাহলে Graph Database ব্যবহার করা ভালো। যেমন — Neo4j।
- স্কেল(Scale): আপনার অ্যাপ যদি ধীরে ধীরে বড় হয়—ব্যবহারকারী বাড়ে, ডাটা বাড়ে তখন ডাটাবেস কত সহজে চাপ সামলাতে পারবে সেটাও মাথায় রাখা জরুরি। সাধারণত Relational Database (যেমন — PostgreSQL, MySQL) ভার্টিক্যাল স্কেলিং-এ (Vertical Scaling) বেশি কার্যকর। মানে আপনার সার্ভার লোড নিতে না পারলে ওই একই মেশিনে আরও বেশি RAM বা পাওয়ারফুল CPU লাগিয়ে একে শক্তিশালী করা।
আর যদি শুরু থেকেই আপনার মাথায় বিশাল স্কেলের (Massive Scale) চিন্তা থাকে, তবে Non-Relational Database (যেমন — MongoDB, Cassandra) বেছে নেওয়া বেশি সুবিধাজনক। এগুলো মূলত হরিজন্টাল স্কেলিং-এ (Horizontal Scaling) পারদর্শী, যেখানে একটা বড় দামী মেশিনের বদলে অনেকগুলো সাধারণ সার্ভার যোগ করেই পুরো সিস্টেমের লোড ভাগ করে নেওয়া যায়।
- ডাটার নির্ভুলতা ও নিরাপত্তা: কিছু সিস্টেমে ভুল ডাটা একেবারেই চলবে না। যেমন—ব্যাংকের লেনদেন, পেমেন্ট, বা ইনভেন্টরি আপডেট। এখানে “প্রায় ঠিক” বলে কিছু নেই, সবকিছু একদম ঠিকঠাক হতে হবে। এমন ক্ষেত্রে Relational Database বেছে নেওয়াই ভালো। যেমন — PostgreSQL, MySQL। এগুলো ACID compliance ফলো করে, মানে একটা অপারেশন সম্পূর্ণভাবে সফল হবে, না হলে একেবারেই হবে না - মাঝামাঝি কিছু থাকবে না।

Section 42: Designing reliable Batch Processing for large-scale data
(নিজের experience থেকে) কয়েক বছর আগে একটা প্রজেক্টে কাজ করছিলাম, যেখানে একটা external API থেকে একসাথে ৫০,০০০ রেকর্ড fetch করতে হতো, তারপর সেগুলো process করে database-এ store করতে হতো।
শুরুতে মাথায় আসলো — আরে এটা আর কী, একবারে সব টেনে এনে কাজ শেষ করি। কিন্তু যত গভীরে গেলাম, তত বুঝলাম ব্যাপারটা এতটা সহজ না।
একসাথে ৫০ হাজার রেকর্ড memory-তে তুললে RAM-এ প্রচণ্ড চাপ পড়ে, Out of Memory error আসার সম্ভাবনা থাকে। তার উপর মাঝপথে যদি server crash করে বা network চলে যায়, তাহলে কিছু data process হবে আর কিছু হবে না — এই অর্ধেক-করা অবস্থাটা কোনো কাজের না, বরং আরও বিপজ্জনক। আর processing চলার সময় যদি মূল table-এর data কেউ বদলে ফেলে, তাহলে পুরো result হবে inconsistent — এটা তো একদমই মেনে নেওয়া যায় না।
তখন কয়েকটা জিনিস করলাম —
- প্রথমত, একবারে সব data না এনে ছোট ছোট batch-এ আনতে শুরু করলাম, ধরো ৫০০ বা ১০০০ করে। Memory-র উপর চাপ অনেকটাই কমে গেল।
- দ্বিতীয়ত, প্রতিটা batch সরাসরি process না করে Message Queue-তে পাঠিয়ে দিলাম। Worker সেখান থেকে একটা একটা করে তুলে কাজ করতো, শেষ হলে সব result একসাথে একটা row হিসেবে database-এ ঢুকতো। এতে কাজটা অনেকটা decoupled হলো, কোথাও failure হলেও queue থেকে আবার তোলা যেতো।
- তৃতীয়ত, প্রতিটা batch-এর processing পুরোটা একটা Transaction-এর মধ্যে রাখলাম। মাঝপথে কিছু একটা হলে পুরো transaction rollback হয়ে যাবে, partial data কোনোভাবেই database-এ ঢুকবে না।
- আর সবশেষে Transaction isolation level হিসেবে REPEATABLE READ বা SERIALIZABLE use করলাম, যাতে পুরো processing সময় জুড়ে data-র একটা consistent snapshot পাওয়া যায়। processing চলাকালীন অন্য কেউ data বদলে দিলেও আমার result-এ তার কোনো প্রভাব পড়বে না।
বড় কাজকে ছোট করে, queue দিয়ে ভাগ করে, transaction দিয়ে নিরাপদ রাখলে — এই তিনটা জিনিস ঠিকমতো করতে পারলে এই ধরনের বেশিরভাগ ঝামেলা এড়ানো সম্ভব।
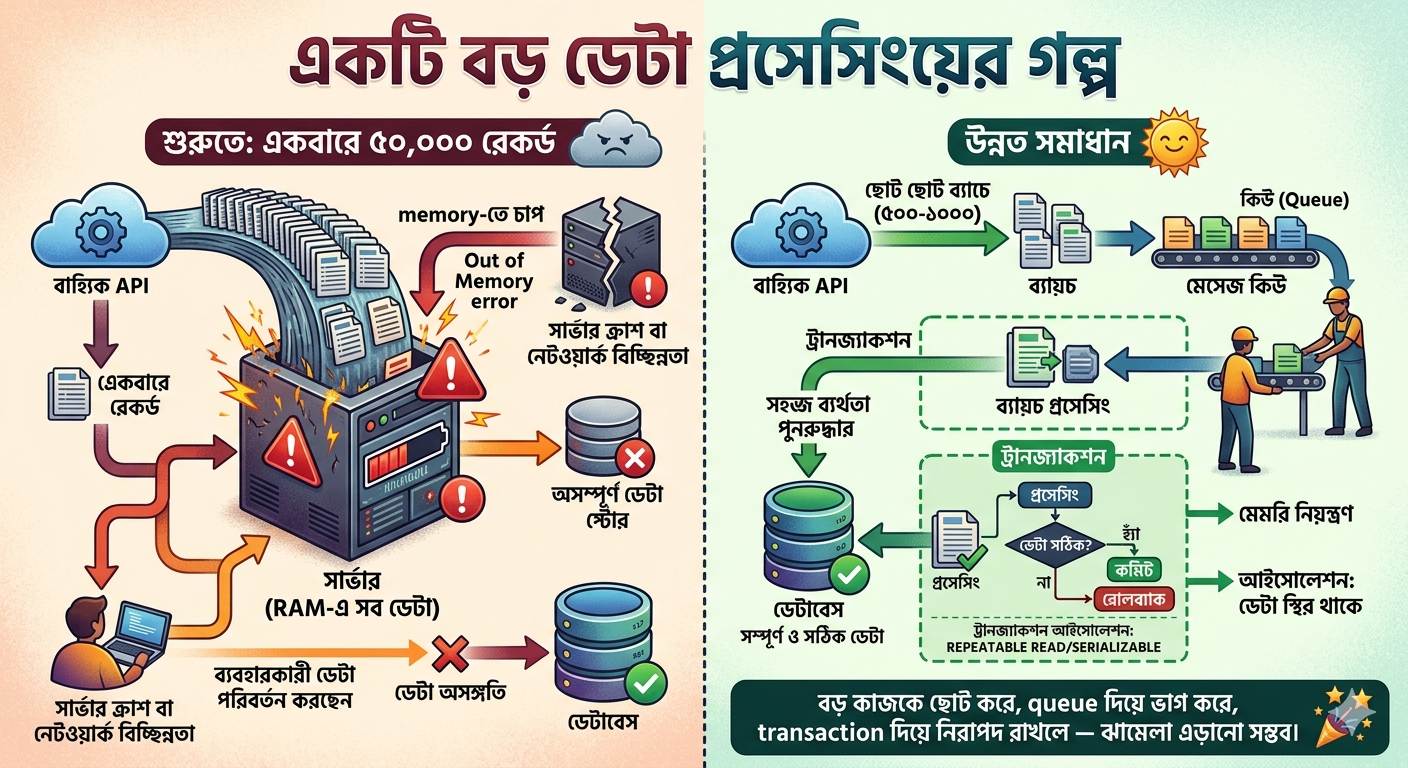
Section 43: High Availability best practices by Netflix
Netflix High Availability নিশ্চিত করার জন্য কিছু টিপস শেয়ার করেছিল(যেগুলো এরা নিজে follow করে থাকে) যা আমাদের অনেক সিস্টেমের কাজে লাগবে,
-
Regional deployment over global ones: Deployment আমরা region by region করবো, যাতে region এ impact টি observe করতে পারি। কোনো প্রকারের সমস্যা হলে আমরা Rollback করে পূর্বের স্টেট এ চলে যেতে পারবো, তখন অন্য region এর উপর কোনো নেগেটিভ ইমপ্যাক্ট পরবে না।
-
Use Blue/Green deployment strategy: এই strategy তে Deploy করার সময় সিস্টেমের দুটি ভার্সন থাকে, Blue হল বর্তমান ভার্সন এবং green হল নতুন ভার্সন। Green ভার্সন টেস্ট করা হয়ে গেলে, সবকিছু ঠিক থাকলে আমরা Blue ভার্সন থেকে সবকিছু Green ভার্সনে নিয়ে যাব।
-
Use deployment windows: Deployment আমরা office hour এবং off-peak এর সময় করব।
-
Enable Chaos Monkey: এটি একটি Tool যা আমাদের production সার্ভারকে ক্র্যাশ করে দিতে পারে। এতে করে আমরা নিশ্চিত হতে পারব আমাদের সিস্টেমটি কত resilience।
-
Deploy exactly what you tested to production: যে পার্ট এর টেস্টিং করা হয় সেই পার্ট Deploy করা হবে।
Original Post: https://netflixtechblog.medium.com/tips-for-high-availability-be0472f2599c
Section 44: Production Outages
Real world production outage আপনাকে শেখায় কীভাবে সিস্টেম outage, কেন outage, এবং কীভাবে দ্রুত recover করতে হয়।
একজন ভালো ইঞ্জিনিয়ার হওয়ার জন্য শুধু সিস্টেম ডিজাইন জানাই যথেষ্ট নয় - outage থেকে শেখা, root cause খুঁজে বের করা, আর সিস্টেমকে আরও resiliant বানানোই আসল দক্ষতা।
Section 45: Real World Problems
একজন ভালো system designer হতে হলে, আমাদেরকে real-world সমস্যাগুলোর requirements এবং planning সঠিকভাবে বুজতে হবে। আমি এখানে কিছু সমস্যা এবং সেই সমস্যাগুলোর সমাধানের ধারা আমি বর্ণনা করছি।
- Design a Highly Concurrent Event Booking System
- Design a Highly Concurrent Event Booking System, with Performance and Consistency in mind
- Design a Scalable One to One and One to Many chat system
- Design a Live Streaming platform like Twitch
- Design DNS that scales to millions of users
- Design an Image Service that supports ~5M uploads/hour (~1.39k uploads/sec)
- Design a High-Scale Unique User Counting System
- Design a Real-time Collaborative Editor
- Design a Content Delivery Network (CDN)
- Design a scalable blob storage like Amazon’s S3
- Design a Zero Downtime Database Migration